Notion API로 로깅 함수 자동 생성하기
DA의 Notion 로깅 명세서를 읽어 TypeScript 로깅 훅을 자동 생성하는 CLI 파이프라인 구현 경험을 공유합니다.
저희 KOIN 프로젝트에서는 사용자 행동 분석을 위해 GA 기반 이벤트 로깅을 운영해왔습니다. 초기 흐름은 단순했습니다. DA(데이터 분석)팀이 Notion에 명세서를 작성하면, FE 개발자가 이를 보고 코드로 옮겼습니다.
겉보기에는 문제 없어 보였지만, 실제 병목은 이 “코드로 옮기는” 과정이었습니다. 한 도메인당 20~30개의 이벤트를 Notion과 에디터를 오가며 타이핑하다 보면 30분 이상이 걸렸고, 오타나 누락이 생기면 DA팀 검수 이후 재작업 요청이 다시 들어왔습니다.

창의적인 작업이라기보다 반복 입력에 가까워, FE 개발자들이 특히 부담을 느끼는 작업 중 하나가 됐습니다.
이 글에서는 위 문제를 해결하기 위해 “Notion 명세서를 읽어 TypeScript 로깅 훅을 자동 생성하는 CLI 파이프라인” 을 구현한 과정을 정리합니다.
1. 해결 방향
자동화의 핵심 아이디어는 간단했습니다.
- Notion API로 명세서를 읽고
- 텍스트를 파싱해서 이벤트 스펙을 추출하고
- TypeScript 코드를 자동 생성한다
목표는 명확했습니다. 30분 걸리는 작업을 1분으로.
2. 기술 스택 선택
Notion API
DA팀이 이미 Notion으로 명세를 작성하고 있었기 때문에 Notion API는 자연스러운 선택이었습니다.
구조화된 데이터베이스에서 필터링과 정렬이 가능했고, 타입 안전한 SDK(@notionhq/client)도 제공됐습니다.
파이프라인 구성
프로젝트와 동일한 TypeScript 환경에서 작업했고, 코드를 세 개의 모듈로 나눴습니다.
scripts/notion/
├── fetch-logging-spec.ts # CLI 진입점
└── lib/
├── types.ts # 타입 정의
├── notion-fetcher.ts # Notion API + 파싱
└── hook-generator.ts # 코드 생성DB 선택과 훅 이름 입력을 위한 대화형 CLI를 만들었고, 주 사용자가 FE 개발자라 CLI 방식에 대한 진입 장벽이 낮다고 판단했습니다.
3. Notion 명세 구조
데이터베이스 스키마
KOIN 프로젝트는 도메인별로 14개의 로깅 데이터베이스를 운영 중입니다.

각 페이지는 다음 필드를 갖습니다:
- 이름: 넘버링 포함 제목 (
11-1. 분실물_글쓰기_클릭) - 상태:
로깅 필요,진행 중,완료,보류 - 플랫폼:
WEB,AOS,iOS
스크립트는 상태가 로깅 필요 또는 진행 중이고 플랫폼이 WEB인 페이지만 가져오도록 구성했습니다.
명세 작성 규칙
각 페이지 본문에는 key:value 형식으로 명세가 작성됩니다.

event_label: shop_categories_order
event_category: click
value: {카테고리명}
duration_time: 이전 카테고리에서 현 카테고리로 이동하는 시간여러 값 중 하나를 선택하는 경우, DA팀은 세 가지 방식으로 작성합니다:
{카드, 신분증, 지갑} # 중괄호
'카드' or '신분증' or '지갑' # or 구분
"카드", "신분증", "지갑" # 쉼표 + 따옴표스크립트는 이 세 패턴을 모두 인식해 TypeScript enum 타입으로 변환합니다.
4. 파이프라인 아키텍처
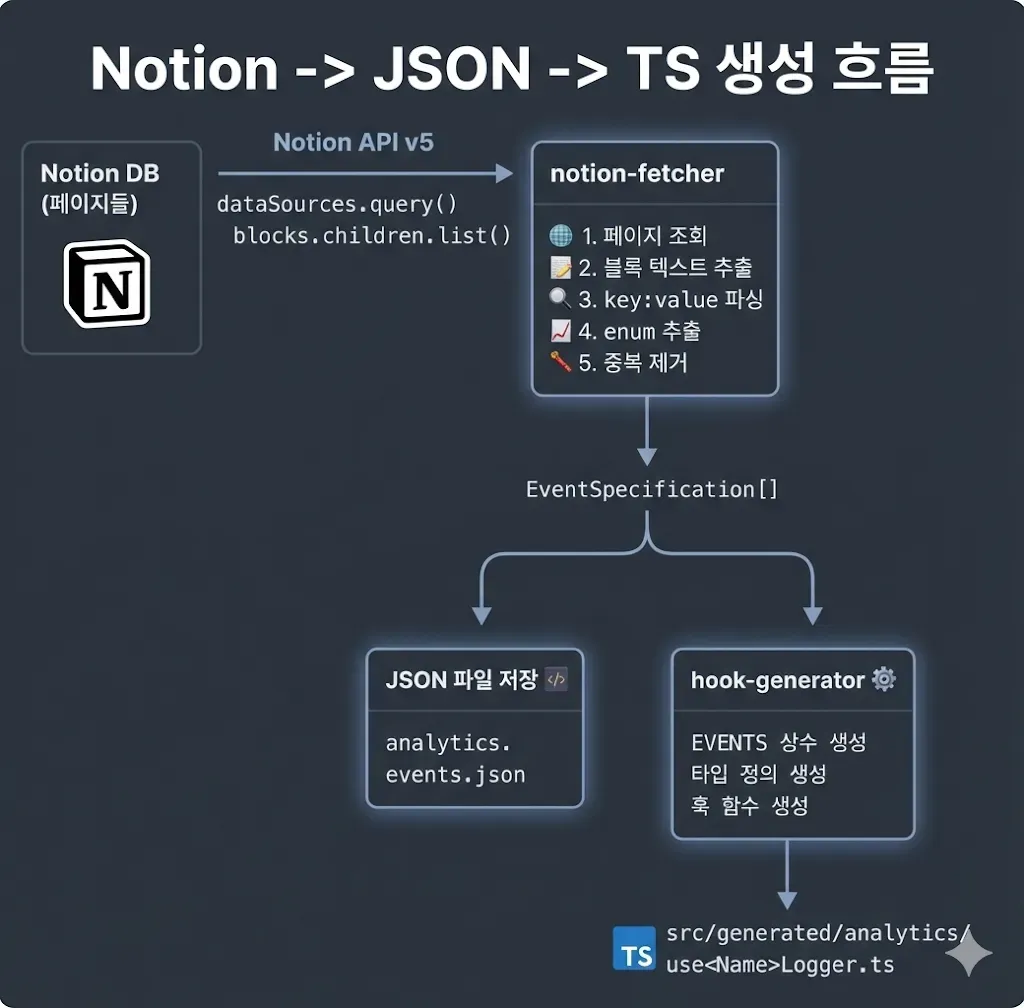
전체 흐름은 다음과 같습니다:
1. Notion 페이지 조회
Notion SDK v5의 dataSources.query로 필터링된 페이지를 가져옵니다.
(database_id → data_source_id 변환 필요)
2. 블록 텍스트 추출
각 페이지의 모든 블록을 재귀적으로 조회해 rich_text를 plain text로 변환합니다.
3. 텍스트 파싱
event_label:, value: 같은 key:value 쌍을 찾고, 앞서 설명한 세 가지 enum 패턴을 감지합니다.
4. 중복 제거
같은 event_label을 가진 여러 페이지가 있으면 values를 병합하고, 넘버링 기준으로 정렬합니다.
5. 코드 생성
EVENTS 상수, 타입 정의, 래퍼 함수를 생성합니다.
5. 핵심 구현
5.1 Notion API 호출
Notion SDK v5는 dataSources.query를 사용하기 때문에, 먼저 database_id를 data_source_id로 변환해야 합니다.
const database = await notionClient.databases.retrieve({ database_id });
const dataSourceId = database.data_sources[0].id;그 다음 필터 조건으로 페이지를 조회합니다.
const response = await notionClient.dataSources.query({
data_source_id: dataSourceId,
filter: {
and: [
{ or: [
{ property: "상태", status: { equals: "로깅 필요" } },
{ property: "상태", status: { equals: "진행 중" } }
]},
{ property: "platform", multi_select: { contains: "WEB" } }
]
}
});페이지네이션은 start_cursor로 처리하고, 각 페이지의 블록을 재귀적으로 조회해서 텍스트를 추출합니다.
Notion 페이지는 블록의 트리 구조라, has_children이 true인 블록은 다시 조회해야 합니다.
5.2 텍스트 파싱
줄바꿈으로 구분된 텍스트에서 key:value 쌍을 추출합니다.
const match = line.match(/^([a-zA-Z_][a-zA-Z0-9_]*)\s*:\s*(.*)$/);
// event_label: shop_categories_order 형식을 파싱value 필드에서 enum을 감지할 때가 핵심입니다.
Notion 에디터가 유니코드 스마트 따옴표("", '')를 사용하기 때문에, 먼저 일반 따옴표로 정규화한 뒤 세 가지 패턴을 검사합니다.
// 패턴 1: {v1, v2, v3}
const braceMatch = text.match(/^\{(.+?)\}/);
// 패턴 2: 'v1' or 'v2' or 'v3'
if (/\bor\b/.test(text)) { ... }
// 패턴 3: "v1", "v2", "v3"
const quoted = [...text.matchAll(/["']([^"']+)["']/g)];2개 이상의 값이 감지되면 value_type: 'dynamic'으로 처리합니다.
5.3 중복 제거
같은 event_label을 가진 여러 페이지가 있을 수 있습니다.
예를 들어, 페이지 A에서 {카드, 신분증}, 페이지 B에서 {지갑, 전자제품}을 정의한 경우죠.
이럴 때는 event_label로 그룹화한 뒤, 모든 values를 병합합니다.
const allValues = new Set<string>();
for (const page of pages) {
page.values.forEach(v => allValues.add(v));
}그리고 타이틀 넘버링(11-1, 11-2)을 파싱해서 정렬합니다.
const match = title.match(/(\d+)-(\d+)/);
// "11-2. 분실물_글쓰기" → [11, 2]5.4 코드 생성
마지막으로 파싱된 이벤트 스펙을 TypeScript 코드로 변환합니다.
생성되는 구조는 세 부분으로 나뉩니다:
1. EVENTS 상수
const EVENTS = {
itemWrite: { event_label: "item_write", value: "글쓰기" },
findUserCategory: {
event_label: "find_user_category",
values: ["카드", "신분증", "지갑"]
},
} as const;2. 동적 값 타입
export type FindUserCategoryValue =
(typeof EVENTS.findUserCategory.values)[number];
// "카드" | "신분증" | "지갑"3. 래퍼 함수
const logFindUserCategory = (value: FindUserCategoryValue) =>
logger.actionEventClick({ team: TEAM, ...EVENTS.findUserCategory, value });snake_case(find_user_category)는 camelCase(findUserCategory)로, 함수명은 log prefix를 붙여 PascalCase(logFindUserCategory)로 변환합니다.
6. 사용 방법
package.json에 스크립트를 추가했습니다:
{
"scripts": {
"log": "tsx scripts/notion/fetch-logging-spec.ts"
}
}터미널에서 yarn log를 실행하면 DB를 선택하고 훅 이름을 입력할 수 있습니다.
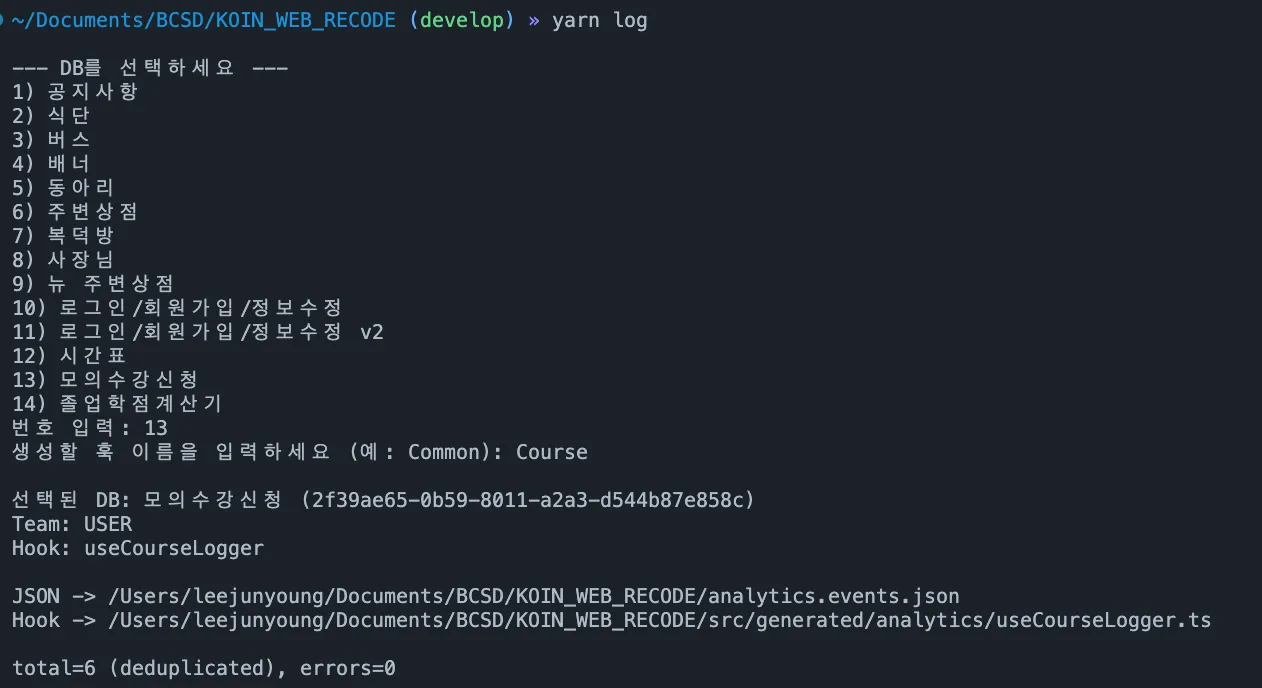
두 개의 파일이 생성됩니다:
analytics.events.json: 디버깅용 이벤트 스펙 (프로젝트 루트)use<Name>Logger.ts: TypeScript 훅 (src/generated/analytics/)
컴포넌트에서는 이렇게 사용합니다:
import { useArticleLogger } from 'generated/analytics/useArticleLogger';
const ArticleWritePage = () => {
const { logItemWrite, logFindUserCategory } = useArticleLogger();
return (
<button onClick={logItemWrite}>글쓰기</button>
);
};logFindUserCategory는 타입이 추론되어, 잘못된 값을 넣으면 컴파일 에러가 발생합니다.
7. 개선 효과
정량적 효과
| 지표 | Before | After | 개선율 |
|---|---|---|---|
| 작업 시간 | 30분 | 1분 | 96% 단축 |
| 이벤트 처리 | 수동 타이핑 | 자동 생성 | - |
| 오타 발생률 | ~5% | 0% | 100% 감소 |
처리 규모:
- 14개 데이터베이스
- 평균 20~30개 이벤트/DB
- 총 약 300개 이벤트 자동화
정성적 효과
1. 휴먼 에러 제거
Notion에 작성된 내용이 그대로 코드로 변환되니, 오타나 누락이 생기지 않습니다.
2. 일관성 있는 코드
모든 로거 훅이 동일한 구조와 네이밍 컨벤션을 따릅니다.
3. DA-FE 협업 개선
DA는 Notion에만 명세를 작성하면 되고, FE는 스크립트만 실행하면 됩니다. DA가 로깅 검수할 때 세부 내용까지 볼 필요가 없어졌습니다.
4. 타입 안전성 향상
기존 수동 코드는 string 타입을 받았지만, 자동 생성 코드는 리터럴 유니온 타입을 씁니다.
// Before
const logCategory = (category: string) => {
/* ... */
};
// After
export type CategoryValue = "카드" | "신분증" | "지갑" | "전자제품" | "기타";
const logCategory = (category: CategoryValue) => {
/* ... */
};8. 디버깅 과정
enum 감지 정확도 보완
처음에는 중괄호 패턴({v1, v2})만 지원했는데, DA팀이 다양한 형식으로 명세를 작성하면서 누락이 발생했습니다.
'v1' or 'v2'형식- 유니코드 스마트 따옴표 (
“”,‘’) - 쉼표로 구분된 따옴표 문자열
DA팀에 형식 통일을 요청할 수도 있었지만, 이미 작성된 명세를 대량 수정하는 비용이 더 컸습니다. 그래서 파서에서 세 가지 패턴을 모두 지원하는 쪽을 선택했습니다.
export function extractEnumValues(raw: string): string[] {
// 유니코드 스마트 따옴표 → 일반 따옴표
const text = raw
.replace(/[\u201c\u201d\u201e\u201f]/g, '"')
.replace(/[\u2018\u2019\u201a\u201b]/g, "'");
// 패턴 1, 2, 3 처리
// ...
}중복 제거 로직 보완
초기 버전에서는 같은 event_label이 여러 페이지에 있으면 첫 번째 페이지만 사용했습니다.
그런데 다른 values를 정의한 경우가 있었습니다:
- 페이지 1:
{카드, 신분증} - 페이지 2:
{지갑, 전자제품}
이 경우에는 병합이 필요했습니다. 그룹화 후 모든 values를 Set에 모아 중복을 제거했습니다.
const allValues = new Set<string>();
for (const page of pages) {
page.values.forEach(v => allValues.add(v));
}9. 배운 점과 한계
코드 생성의 장점
1. 일관성
모든 로거 훅이 동일한 템플릿을 따라서, 개발자마다 다른 스타일로 작성하는 문제가 사라졌습니다.
2. 속도
30분 걸리던 작업이 1분으로 줄었습니다. 반복 작업에 쓰던 시간을 다른 곳에 쓸 수 있게 됐습니다.
3. 유지보수
템플릿만 수정하면 모든 훅을 일괄 업데이트할 수 있습니다.
logger.actionEventClick 시그니처가 바뀌면 hook-generator.ts만 수정하고 재생성하면 됩니다.
코드 생성의 단점
1. 유연성 부족
특수한 케이스를 처리하기 어렵습니다. 특정 이벤트에만 추가 로직이 필요하면, 생성된 코드를 수동으로 고쳐야 합니다.
2. 템플릿 의존
비즈니스 로직이 템플릿에 강하게 묶입니다. 구조를 크게 바꾸려면 템플릿과 파싱 로직을 모두 수정해야 합니다.
3. 검증 부재
생성된 코드가 정확한지 검증하는 단계가 없습니다. DA가 Notion에 잘못 쓰면, 그대로 코드로 변환됩니다.
향후 개선 방향
1. 생성 코드 자동 테스트
생성된 훅이 제대로 동작하는지 검증하는 테스트를 추가하려고 합니다.
2. GitHub Actions 자동화
Notion에 명세가 추가되면 자동으로 코드를 생성하고 PR을 만드는 워크플로우를 구상 중입니다.
3. 변경 감지
Notion 페이지의 last_edited_time을 추적해서, 바뀐 명세만 재생성하면 더 효율적일 것 같습니다.
10. 마무리
결론부터 말씀드리면, 이번 작업에서 가장 크게 확인한 점은 반복 작업 자동화의 효과였습니다.
반복 작업의 자동화 가치
30분짜리 작업도 반복되면 팀 비용이 빠르게 커집니다. 자동화에 투입한 시간은 몇 주 안에 회수됐습니다.
팀 협업 개선
DA-FE 간 소통 비용도 크게 줄었습니다. DA는 Notion 명세에 집중하고, FE는 생성된 코드를 바로 사용할 수 있게 됐습니다.